Live-Wissensdatenbank für Normen, Artikellisten, Kundenanforderungen und Projektdokumente
In modernen Engineering-Projekten (Elektrokonstruktion, Maschinenbau, Automatisierung, Sondermaschinen) arbeiten Teams ständig mit komplexen Vorgabedokumenten, darunter:
- Artikel- und Materiallisten
- Kundenspezifikationen
- Normensammlungen (DIN, ISO, VDE)
- Freigabedokumente & Änderungsstände
- EPLAN-Auszüge
- Risikoanalysen
- Lastenhefte und Funktionsbeschreibungen
Diese Informationen müssen versioniert, durchsuchbar, projektbezogen, aktuell und teamweit verfügbar sein.
Hier setzt unser RAG-unterstütztes Engineering-Wissenssystem an.
🧠 Ziel des Systems
Eine projektorientierte, KI-gestützte Live-Wissensdatenbank, die:
- Automatisch Dokumente aus Nextcloud einliest
- Texte, Tabellen, Normartikel, technische Inhalte extrahiert und strukturiert
- OCR für gescannte PDFs nutzt
- Alles in eine Postgres/PGVector-Datenbank schreibt
- Änderungen in Echtzeit erkennt
- Veraltete Daten automatisch löscht
- Eine KI-Chatoberfläche (Open-WebUI) benutzt, um Fragen projektbezogen zu beantworten
- Inhalte nicht erfindet, sondern nur referenziert
- Tabellen per SQL auswertet (z. B. „zeige alle Artikelgrößen“, „max. Stromstärke“ usw.)
- Bilder extrahiert, in Supabase lädt und korrekt im Markdown ausgibt
Damit hat das Engineering-Team einen digitalen Projektingenieur, der alle Dokumente kennt, sie durchsucht, interpretiert und vergleicht.
🏗️ Architekturüberblick
Der Workflow besteht aus drei zentralen Bereichen:
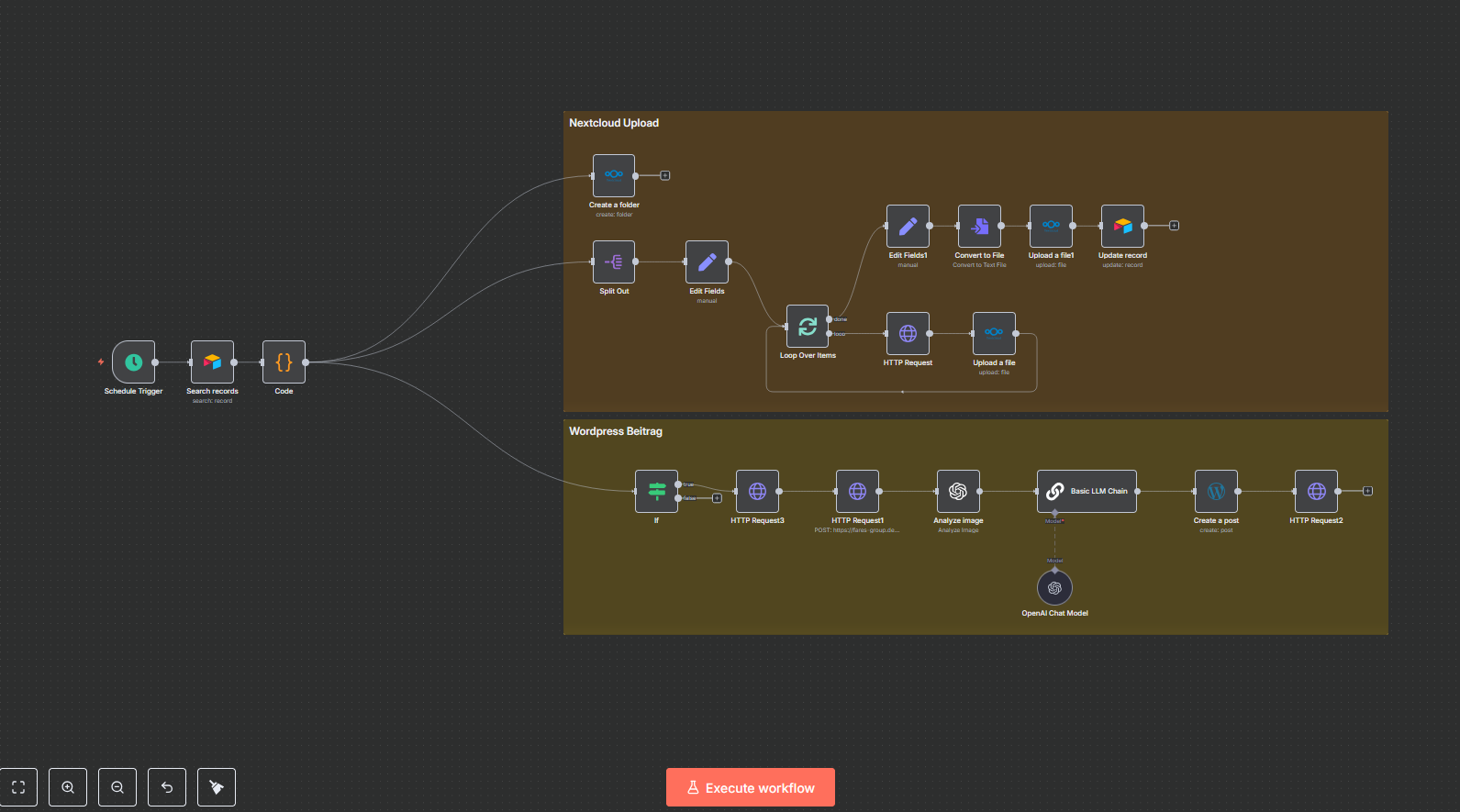
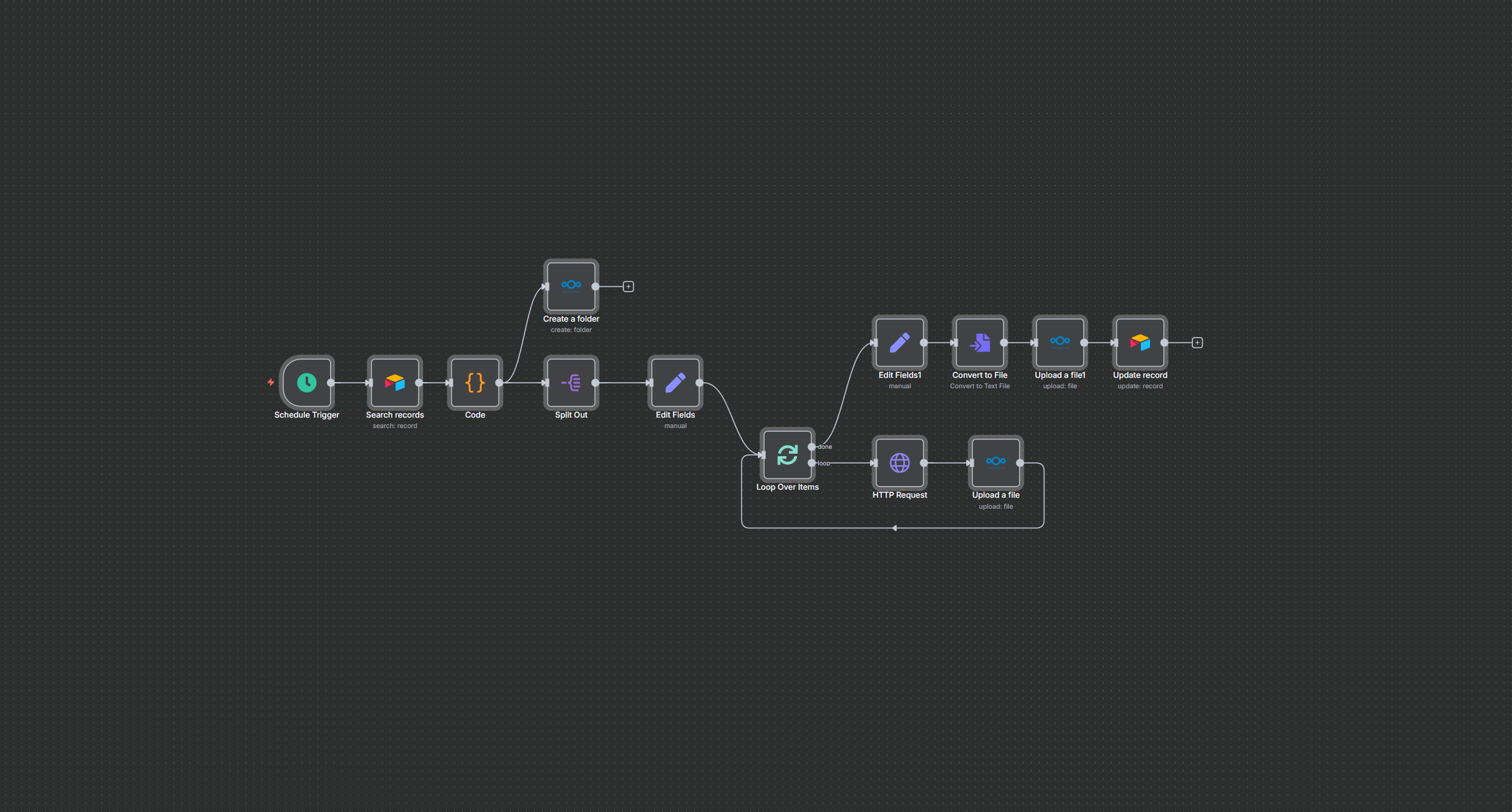
1️⃣ Dokument-Ingestion & Synchronisation (Nextcloud → RAG-Datenbank)
🔁 Alle 5 Minuten:
- Nextcloud-Ordner scannen
–/Dokumente/n8n/RAG/… - Gegen Postgres vergleichen (ETag + LastModified)
➜ nur neue oder geänderte Dateien werden eingelesen. - Veraltete Einträge entfernen
– aus:document_metadatadocument_rowsdocuments_pg(Vektorstore)
- Neue/aktualisierte Dateien einlesen
- Dateityp bestimmen (PDF, Excel, CSV, DOCX …)
- Tabellen extrahieren (CSV/XLSX)
- Text extrahieren (Default Loader)
- OCR verwenden wenn nötig
(für gescannte PDFs ➜ Mistral OCR)
- Dokument in Chunks splitten + speichern
➜ als Vektoren indocuments_pg
Damit wird jede Änderung sofort übernommen.
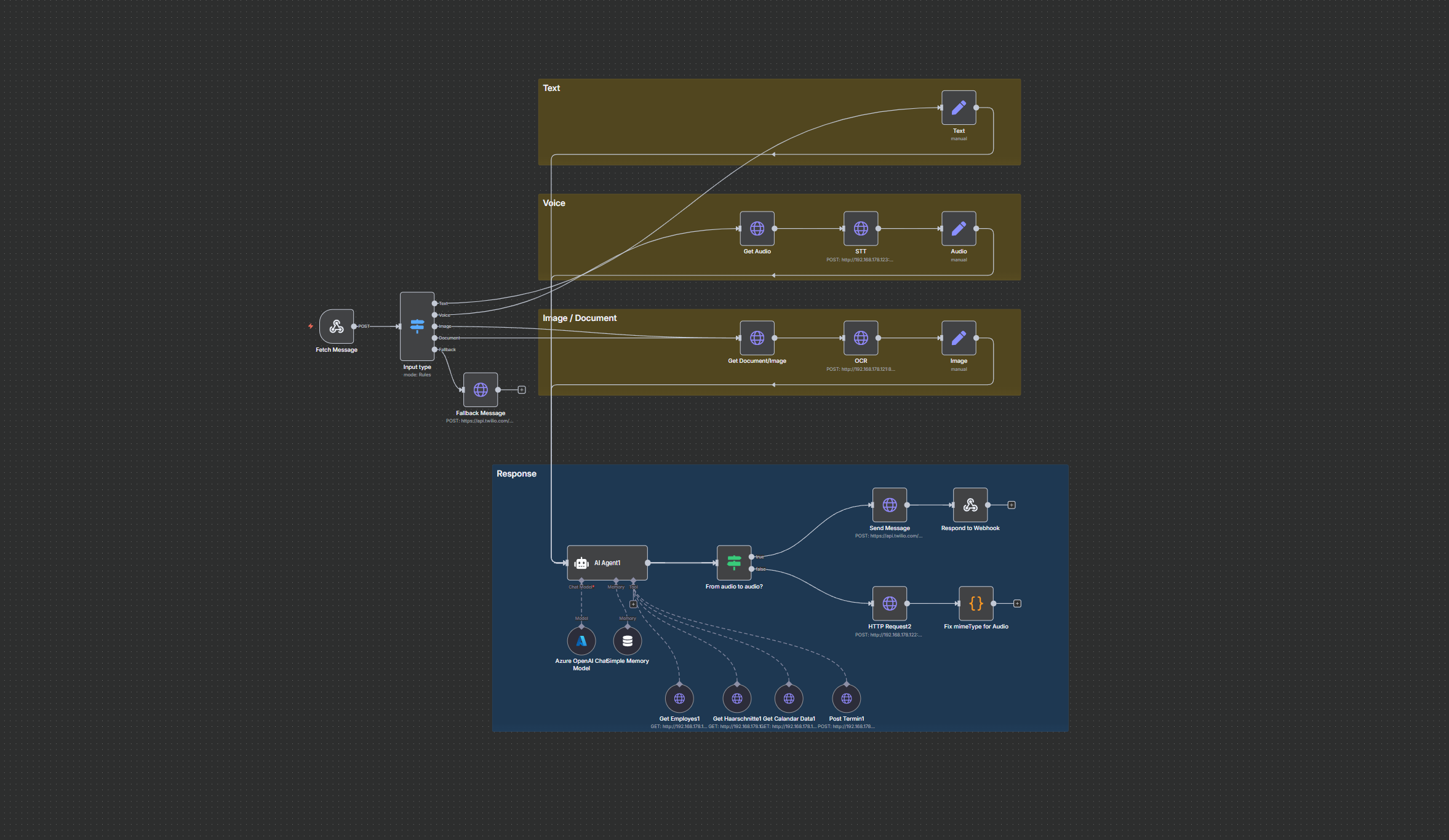
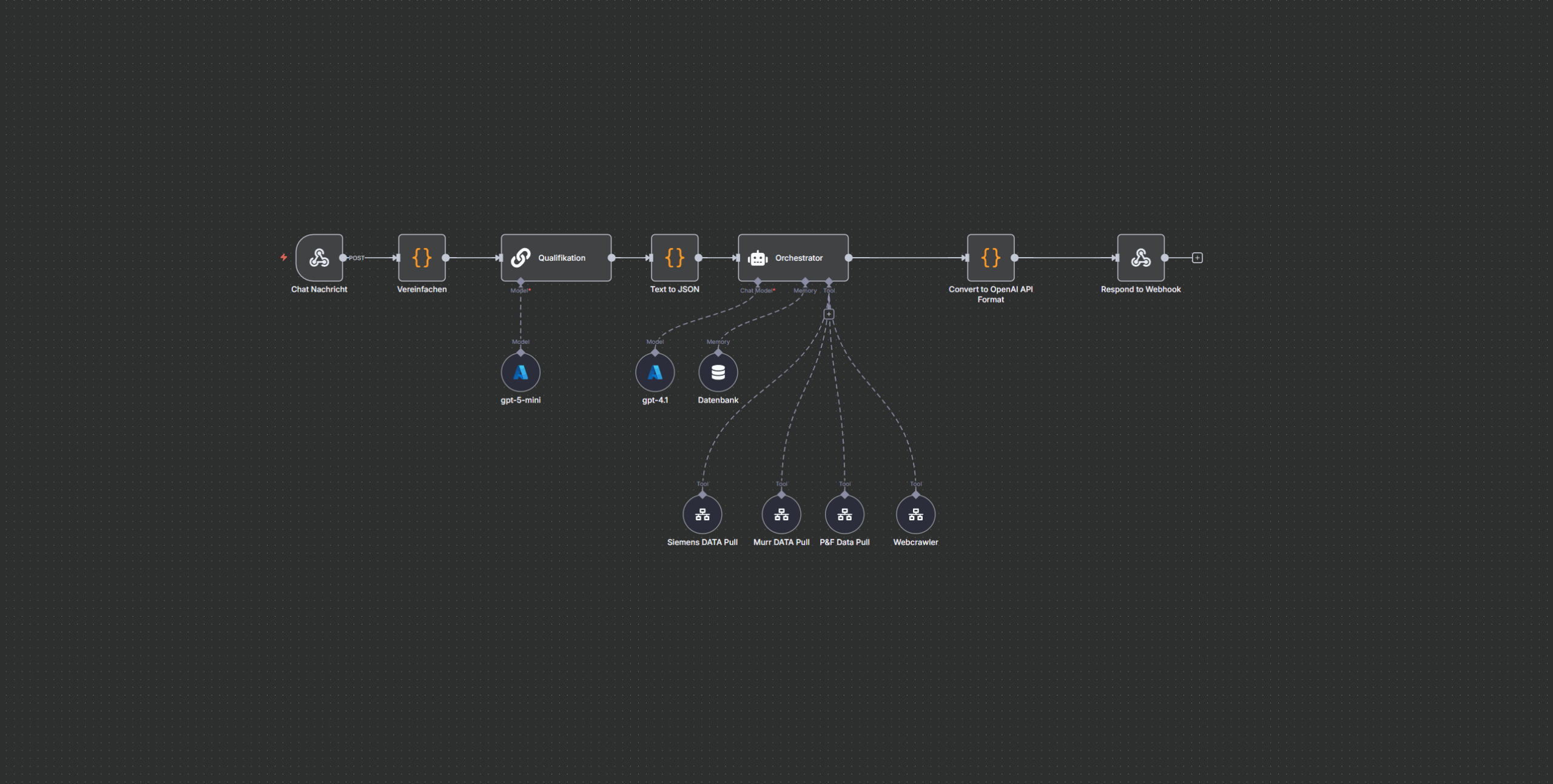
2️⃣ RAG-KI-Agent (Open-WebUI)
Der Chat läuft über:
- Azure OpenAI (DSGVO-konform)
Modelle:gpt-5-mini,gpt-4.1-mini, Embeddings - Postgres Vektorsuche (PGVector)
- KI-Gedächtnis über Postgres Chat Memory
Der Agent erhält ein strenges System-Prompt:
✔ Keine Halluzinationen
✔ Immer RAG-Suche -> Dokumente referenzieren
✔ SQL-Abfragen für tabellarische Daten
✔ Markdown-strukturierte Antworten
✔ Anzeigen aller Bilder (automatisch aus Supabase)
Beispielprompt:
„Suche bitte die genaue Normstelle für Kurzschlussfestigkeit aus den hochgeladenen Kundenvorgaben.“
Der Agent durchsucht:
- kundenspezifische Vorgaben
- Normen (z. B. DIN EN 61439)
- technische Anhänge
- Excel-Stücklisten
- Tabellen zur Strombelastbarkeit
- Maschinenrichtlinien-Auszüge
und liefert exakte, belegte Antworten.
3️⃣ Dynamischer Dokument-Parser
(OCR → Bildextraktion → Supabase → Markdown-Rekonstruktion)
Der zweite Workflow:
- Hochladen eines PDF/Dokuments zu Mistral API
- Generierung einer signierten URL
- OCR-Prozess mit:
- Textextraktion
- Erkennung aller Bilder
- Erstellung natürlicher Bildbeschreibungen
- Speichern aller Bilder via Supabase
- Ersetzen aller inline-Bild-IDs im Markdown
- Zurückgeben eines vollständig rekonstruierten Markdown-Dokuments
– mit Bildern
– mit Bildbeschreibungen
– perfekt geeignet für RAG
Beispiel:

→ wird ersetzt durch →

Die Abbildung zeigt die Verdrahtung eines Motorschützes mit Überlastschutz…
🛠️ Was wird gespeichert?
1. document_metadata
- file_id (ETag)
- title
- url (Nextcloud-Pfad)
- last_modified
- schema (bei Tabellen)
2. document_rows
- Jede Tabellenzeile als JSON
Beispiel für Artikeldaten:
{
"Artikelnummer": "X20392",
"Bezeichnung": "Sicherungsautomat 10A",
"Hersteller": "Siemens",
"Norm": "DIN EN 60898",
"Strom": "10A"
}
3. documents_pg (Vektorstore)
- alle Textchunks
- inklusive OCR-Texte
- inklusive Bildbeschreibungen
⚙️ Use-Cases in Engineering-Projekten
🔌 Elektroplanung / Schaltschrankbau
- automatische Ermittlung der richtigen Normstellen
- Prüfung ob Komponenten normkonform sind
- Zeigen von Artikeln aus einer Liste
⚙️ Maschinenbau / Mechanik
- Normanforderungen für Sicherheit (z. B. ISO 12100)
- automatisches Auslesen von Lastenheften
- OCR lesbarer gescannter Werkstattnotizen
- Inhaltliche Zusammenführer unterschiedlicher Revisionen
📑 QM & Dokumentation
- zentraler Norm-Wissensspeicher
- projektbezogene Vorgabensammlung
- automatisches Änderungsmanagement
- Rückverfolgbarkeit aller Vorgaben
💡 Engineering-KI | Beispielabfragen
- „Welche Artikel sind im Projekt XY freigegeben?“
- „Welche Norm fordert den Überstromschutz der 24V-Schiene?“
- „Vergleiche die Kundenanforderungen Version 2.1 und 3.0.“
- „Welche Motorleistung ist laut Vorgabe zulässig?“
- „Liste alle Artikel mit größerem Nennstrom als 16A.“
- „Welche Dokumente wurden seit gestern geändert?“
📈 Vorteile für Engineering-Firmen
❤️ Für Konstrukteure
- Keine Sucherei in 300 PDFs
- Sofort Antworten auf Normfragen
- Projektbezogene Wissensbasis — nie wieder alte Dokumentstände
🧠 Für Projektleitung
- Versionssicherheit
- Vollautomatisches Änderungsmonitoring
- Revisionssichere Ablage
⚡ Für die Firma
- Weniger Fehler
- Schnellere Konstruktion
- Saubere, nachvollziehbare Dokumentation
- Compliance-sichere Normanwendung
🧩 Technologiestack
| Bereich | Lösung |
|---|---|
| Dateiablage | Nextcloud |
| OCR | Mistral |
| KI Modelle | Azure OpenAI (DSGVO) |
| Datenbank | Supabase Postgres + PGVector |
| Orchestrierung | n8n |
| Workspace | Open-WebUI |
| Embeddings | text-embedding-3-small |
| Reranker | Cohere Reranker |
| Versionierung | ETag + LastModified Vergleich |
🎯 Fazit
Dieser Workflow transformiert deine Engineering-Firma in einen datenbasierten, KI-gestützten High-Performance-Prozess:
✔ alle Kundenvorgaben
✔ alle Normen
✔ alle Artikellisten
✔ alle Freigaben
✔ alle Projektfiles
✔ alle Tabellen
✔ alle Bilder
✔ alle OCR-Inhalte
werden vollautomatisch eingelesen, versioniert, durchsuchbar gemacht, mit KI analysierbar und projektbezogen live aktuell gehalten.