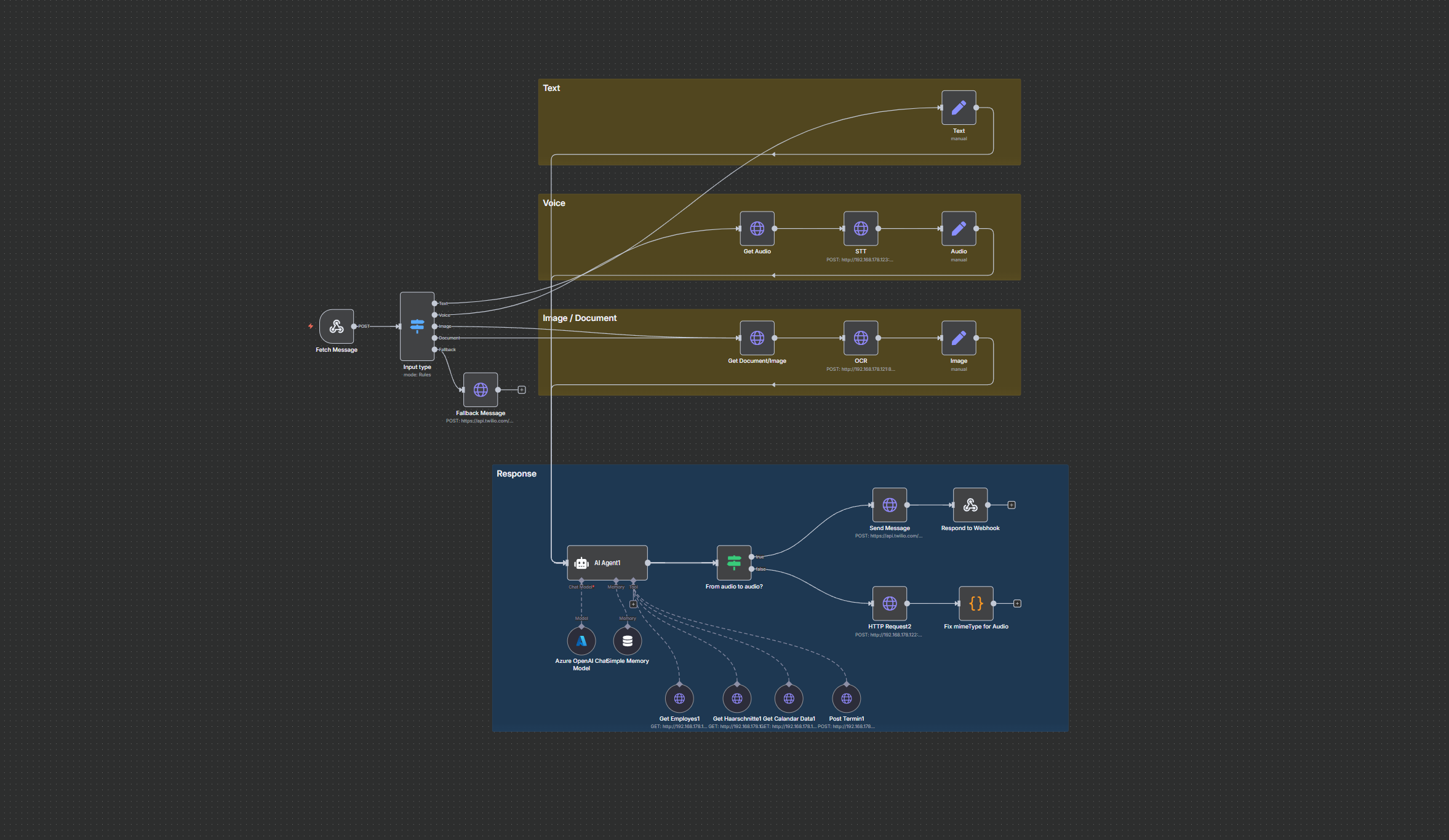
Ausgangssituation
Bei einem unserer Kunden werden täglich zahlreiche Dokumente gescannt – Rechnungen, Lieferscheine, Verträge oder Notizen. Diese landen automatisch in einem Nextcloud-Ordner und stehen anschließend verschiedenen Mitarbeitern zur Verfügung.
Das Problem: Die PDFs stammen direkt aus dem Scanner und enthalten keine durchsuchbaren Texte. Damit war die Suche nach Dokumenteninhalten oder Beträgen mühsam, und eine revisionssichere Langzeitarchivierung im PDF/A-Format war nicht gewährleistet.
Der Kunde wünschte sich eine vollautomatische Lösung, um neue Scans in Nextcloud automatisch zu erkennen, in durchsuchbare PDF/A-Dateien zu konvertieren und anschließend sauber abzulegen – ohne Cloud-Dienste, vollständig on-premises.
Unsere Lösung: n8n + Nextcloud + lokaler OCR-API-Server
Wir haben dafür einen Workflow auf Basis von n8n entwickelt, der direkt mit der Nextcloud des Kunden verbunden ist.
Der Ablauf im Überblick:
- Überwachung des Scanner-Ordners:
In regelmäßigen Intervallen prüft der Workflow den Nextcloud-Ordner/Geschaeftsdaten/Scannerauf neue Dateien. - Filterung & Verarbeitung:
Bereits verarbeitete Dokumente (erkennbar an der Endung_ocr.pdf) werden übersprungen, um doppelte Konvertierungen zu vermeiden. - Lokale OCR-Verarbeitung:
Neue PDF-Dateien werden automatisch an einen lokalen OCR-API-Server geschickt, der innerhalb der Kundeninfrastruktur läuft.
Dieser Server basiert auf FastAPI und nutzt internocrmypdfmit der OCR-Engine Tesseract.
Unterstützt werden mehrere Sprachen (z. B. Deutsch & Englisch), automatische Drehung, Schräglagenkorrektur und Optimierung.
Das Ergebnis ist ein PDF/A-konformes Dokument mit Textlayer – also durchsuchbar, normgerecht und visuell identisch zum Original. - Rückführung & Ablage:
Das erzeugte_ocr.pdfwird im gleichen Ordner wieder hochgeladen.
Das ursprüngliche Scan-PDF wird – je nach Einstellung – gelöscht, um Dubletten zu vermeiden. - Automatische Namenskonvention:
Der Workflow ergänzt alle OCR-Dateien einheitlich mit der Endung_ocr.pdfund sorgt so für klare Versionierung und Nachvollziehbarkeit.
Datenschutz & Sicherheit: Verarbeitung ausschließlich lokal
Ein zentrales Ziel dieses Projekts war der Datenschutz.
Alle Verarbeitungsschritte finden innerhalb der Kundensysteme statt – keine Datei verlässt das lokale Netzwerk.
Architektur
- FastAPI-Server läuft on-prem auf einem Linux-System im Intranet.
- Der OCR-Service nutzt ausschließlich temporäre Arbeitsverzeichnisse (
tempfile.TemporaryDirectory), die nach jedem Auftrag automatisch gelöscht werden. - Der Server akzeptiert nur PDF-Dateien (
Content-Type: application/pdfoder multipart upload). - Das Ergebnis wird gestreamt zurückgegeben – keine Kopien im Speicher, keine dauerhafte Speicherung.
Datenschutzvorteile
- Daten bleiben im Haus: Keine Übertragung in fremde Clouds oder Drittländer.
- Verarbeitung zweckgebunden: Nutzung nur zur Texterkennung.
- Speicherbegrenzung: Temporäre Daten werden nach Verarbeitung automatisch gelöscht.
- Transparente Benennung: Jede OCR-Datei trägt den Suffix
_ocr.pdf– klar nachvollziehbar. - Keine Protokollierung von Inhalten: Nur technische Logs (Status, Dauer, Erfolg/Fehler).
Technische Härtung
- Zugriff nur über interne IPs oder VPN.
- HTTPS (TLS)-Absicherung über Reverse Proxy mit
Strict-Transport-Security&Referrer-Policy. - API-Key oder mTLS-Authentifizierung für n8n-Aufrufe.
- Rate-Limits & Timeouts schützen vor Missbrauch.
- Kein Internetzugang vom Server ausgehend (reine Intranet-Kommunikation).
- Antivirus-Option (ClamAV) möglich – vor OCR-Aufruf zur zusätzlichen Prüfung.
Beispielheader (Reverse Proxy)
X-Content-Type-Options: nosniff
Content-Security-Policy: default-src 'none'
Strict-Transport-Security: max-age=31536000; includeSubDomains
Referrer-Policy: no-referrer
So entsteht eine vollständig datenschutzkonforme On-Prem-Lösung, die nicht nur sicher, sondern auch technisch elegant umgesetzt ist.
Vorteile für den Kunden
- Automatische Texterkennung: Dokumente sind durchsuchbar in Nextcloud & Desktop-Suche.
- Langzeitarchivierung: Ausgabe als PDF/A – rechtssicher und standardkonform.
- Volle Kontrolle: Alle Daten bleiben im eigenen Netzwerk.
- Zeitersparnis: Kein manuelles OCR mehr notwendig.
- Einheitliche Ablage:
_ocr.pdf-Suffix für klare Nachvollziehbarkeit. - DSGVO-konform: Keine Übermittlung, keine Fremdsysteme, keine Drittanbieter.
Technische Eckpunkte
- Workflow Engine: n8n (Automatisierung & Orchestrierung)
- Cloud-System: Nextcloud mit OAuth2-Anbindung
- OCR-Service: FastAPI + ocrmypdf + Tesseract
- Sprachen: Deutsch & Englisch (
lang=deu+eng) - Output: PDF/A mit Texterkennung, Rotation, Deskew, Optimierung
- Dateibenennung: Original →
_ocr.pdf - Timeout: bis zu 15 min für große Dokumente
- Laufzeitumgebung: On-prem Linux, ohne Internetzugang
Erweiterung & Ausblick
In der nächsten Ausbaustufe kann der Workflow erweitert werden, um:
- automatisch Metadaten zu extrahieren (Datum, Lieferant, Rechnungsnummer),
- Dokumente zu taggen oder in Unterordner zu verschieben,
- Benachrichtigungen in Nextcloud Talk oder per Mail zu senden,
- oder eine Anbindung ans ERP/DMS-System zu schaffen.
Fazit
Mit dieser Lösung erhält der Kunde eine automatisierte, sichere und revisionssichere Dokumentenverarbeitung – komplett lokal betrieben, ohne Cloud-Dienste, ohne Datenschutzrisiko.
Der Workflow läuft im Hintergrund, ist wartungsarm und sorgt dafür, dass alle gescannten Dokumente in Nextcloud durchsuchbar, standardisiert und sicher archiviert sind.